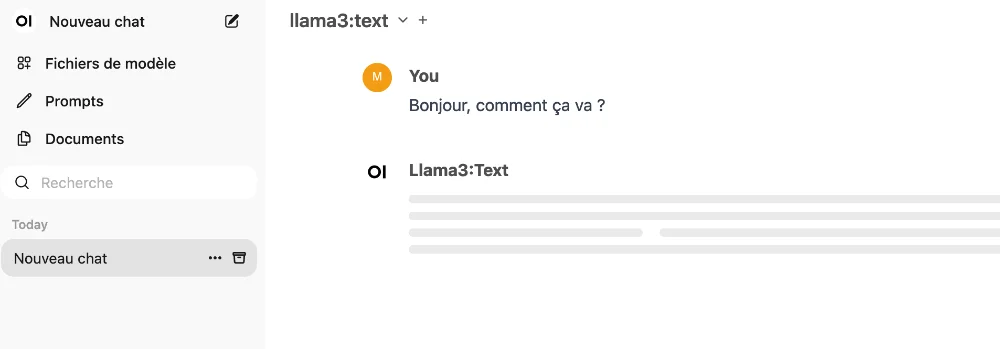
Open WebUI débarque pour changer notre façon d’interagir avec Ollama grâce à une interface graphique intuitive et ergonomique ! Parce que l’IA, c’est cool, mais si c’est simple à utiliser, c’est encore mieux. Ollama pour rappel, c’est un outil qui permet de faire tourner des LLM en local et qui s’utilise soit via du code, soit directement en ligne de commande.
Avec Open WebUI, vous allez enfin avoir une interface web personnalisable avec votre thème, sombre pour les hackers en herbe ou clair pour les âmes sensibles, dans la langue de votre choix, de l’anglais au klingon en passant par le français, et vous pourrez ainsi causer avec Ollama comme si vous étiez sur ChatGPT. Avec le support de Markdown, de LaTeX et de la coloration syntaxique, vous pourrez même lui faire cracher du code et des formules mathématiques comme jamais.

Open WebUI permet même d’utiliser plusieurs modèles en parallèle, comparer leurs réponses, et même les faire discuter entre eux… Et si vous voulez de l’interaction plus poussée, lâchez-vous avec les fonctionnalités de Récupération Augmentée (RAG). Vous pourrez intégrer des documents externes dans vos conversations et même aller les chercher directement sur le web grâce à une fonction de navigation intégrée.
Avec l’outil de création de fichiers modèle (modelfiles), vous pouvez également définir des agents conversationnels sur mesure et les partager avec la communauté Open WebUI.
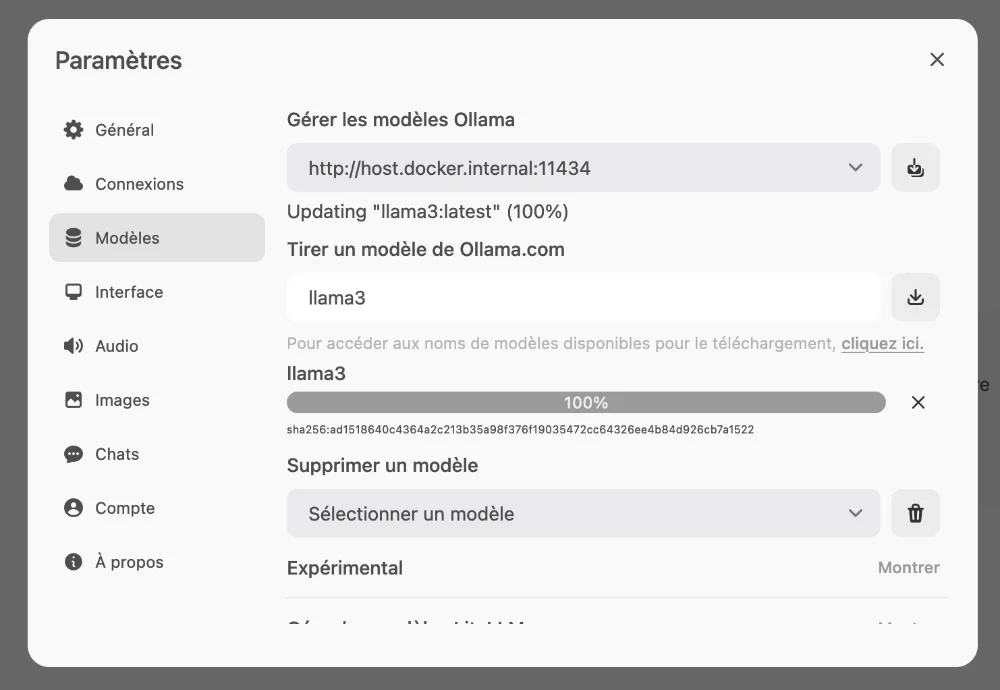
Bien sûr, comme tout bon logiciel qui se respecte, Open WebUI gère la reconnaissance vocale, la synthèse Text-to-Speech et même la génération d’images avec DALL-E et d’autres systèmes compatibles. Cadeau bonux, l’intégration avec les API compatibles OpenAI, pour encore plus de possibilités déjantées.
Pour plus d’informations sur ces fonctionnalités et comment les configurer, consultez la documentation officielle d’Open WebUI.
C’est open source, c’est puissant, c’est customisable à outrance alors que vous soyez un champion du dev ou comme moi, juste un curieux qui veut s’amuser avec l’IA, vous allez vous régaler.
Avant de vous lancer dans l’installation d’Open WebUI, assurez-vous d’avoir les prérequis suivants :
- Docker installé sur votre machine
- Une URL de base pour Ollama (OLLAMA_BASE_URL) correctement configurée
Pour configurer l’URL de base d’Ollama, vous pouvez soit la définir en tant que variable d’environnement, soit la spécifier dans un fichier de configuration dédié.
Une fois les prérequis remplis, vous pouvez procéder à l’installation d’Open WebUI en utilisant Docker :
docker run -d -p 3000:8080 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Cette commande va télécharger l’image Docker d’Open WebUI et lancer un conteneur accessible sur http://localhost:3000.
Amusez-vous bien et si vous voulez en savoir plus, toutes les infos sont ici.




